Una de las actividades críticas en la industria de seguros es el procesamiento de reclamos, el cual es un proceso que históricamente ha dependido de extensa interacción humana. Machine Learning puede ayudar a agilizar el flujo de los reclamos mediante la automatización de su ciclo completo, desde el levantamiento del reporte inicial hasta el cierre del reclamo con el cliente.
Aplicaciones
Machine Learning
Machine Learning
Procesamiento Inteligente de Reclamos

Machine Learning nos ayuda a enfocarnos en lo más importante
Un ejemplo específico de cómo Machine Learning habilita la automatización del proceso de reclamos son herramientas de extracción de datos en documentos, ya sea escritos a mano o en máquina, de una manera muy rápida y extremadamente eficiente. Como resultado, en lugar de pasar horas capturando información, los empleados pueden enfocar sus esfuerzos en casos más complejos o de mayor valor estratégico para la compañía.
¿Es esta herramienta capaz de superar el trabajo de captura manual de un humano? Considerando un caso de estudio donde utilizando la herramienta Vidado se logró capturar la información de 1 millón de pólizas en 7 meses con una precisión de 97.3%, la respuesta es un contundente sí.

Bag of Words: Procesado de texto ignorando el
orden de las palabras.

Análisis de sentimiento: Comprender
actitudes, opiniones y emociones a través de datos.

Aprendizaje no supervisado: Comprensión y
abstracción de patrones de información para predecir un resultado.
Evaluación automatizada de daños
Las aseguradoras pueden explotar técnicas de Machine Learning para el reconocimiento de patrones más allá de la digitalización de documentos, siendo posible la automatización de procesos más complejos como la evaluación de daños, a través del reconocimiento de imágenes y video.
Utilizando bases de millones y millones de imágenes es posible entrenar un modelo para llevar a cabo una evaluación de daños, ya sea de autos u otro tipo de propiedad, así como un ajustador lo hace hoy en día – la gran diferencia recae en que el modelo hará esta evaluación de manera más precisa, expedita, consistente y objetiva.
El impacto de la utilización de Machine Learning en el proceso de evaluación es claro:
- Reducción de tiempo necesario para evaluar los daños en un siniestro.
- Aumento en calidad de datos.
- Evitar errores derivados de una captura manual.
Conceptos aplicados

Bag of Words: Procesado de texto ignorando el
orden de las palabras.

Análisis de sentimiento: Comprender
actitudes, opiniones y emociones a través de datos.
Segmentación de clientes en préstamos automotrices
Machine Learning puede mejorar la aprobación del proceso de préstamos tradicional, donde un motor basado en reglas calcula un puntaje basado en variables de datos, como historial crediticio, ingresos, empleador, pago inicial y otra información financiera y el buró de crédito.
Mediante la inclusión de datos del concesionario, centro de llamadas, agencias de cobranza y décadas de recopilación de datos históricos, pueden obtenerse análisis que permitan predecir el cumplimiento o retraso en los pagos del cliente, permitiendo una mejor toma de decisiones al momento de definir si se acepta o rechaza un préstamo. Con esta capacidad adicional de predicción, las compañías de seguros pueden reducir el riesgo de otorgar un crédito, aumentar las tasas de aprobación para clientes potenciales y aumentar su retorno de inversión, (Si es aceptado o rechazado, monto, intereses, plazos, etc.)
Además de las aprobaciones, Machine Learning puede ayudar a las empresas de préstamos automotrices a identificar segmentos desatendidos y establecer variables personalizadas como tasas de interés, montos de préstamos, plazos, etc.

Reducción de tiempo necesario para evaluar los daños en un siniestro.
Aumento en calidad de datos.
Evitar errores derivados de una captura manual.
Te ayudamos a automatizar los procesos de tu empresa.
Optimización de Inversión en Publicidad en Redes
Sociales
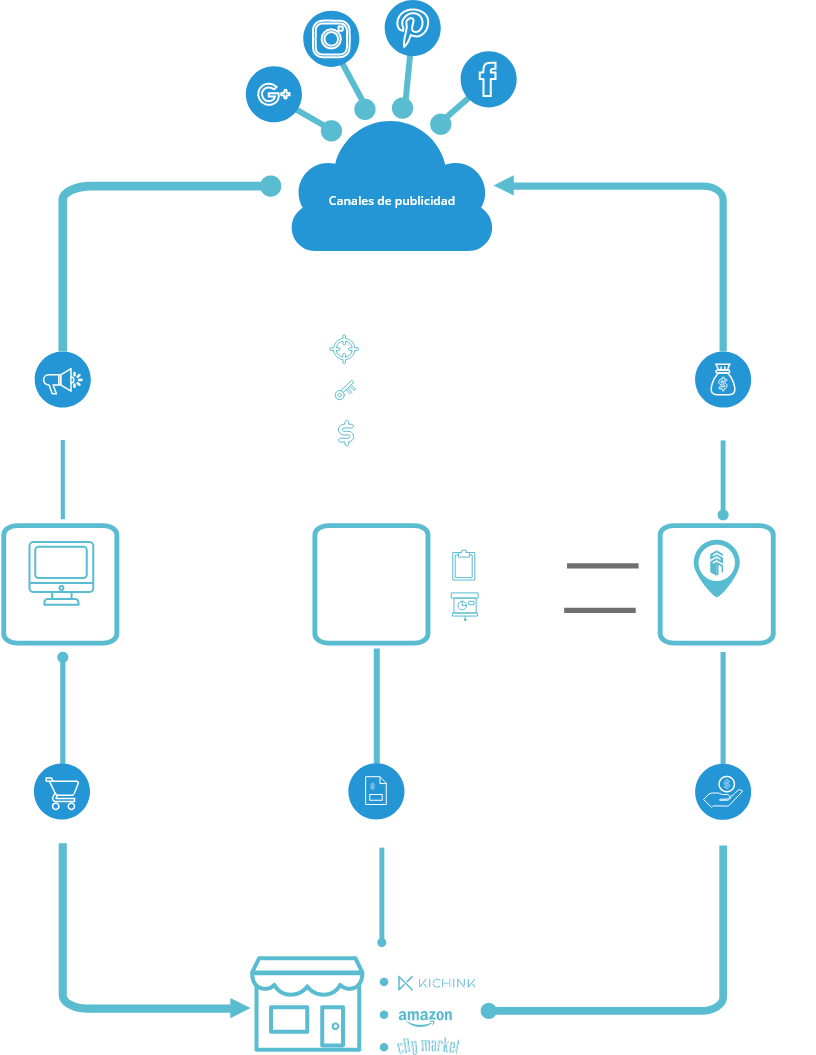
Dentro del sector de Retail hemos ayudado a nuestros clientes a incrementar sus ventas identificando segmentos de mercado en las redes sociales y llevando a cabo campañas de venta dirigidas. Esto se logra cruzando los datos históricos de tres fuentes principales:
-
Tráfico en Redes Sociales y motores de búsqueda:
Facebook, Instagram, Pinterest, Google, otras.
-
Canales de venta:
eCommerce y establecimientos físicos.
-
Evitar error Información de inversión en publicidad en redes
sociales:
Sistemas contables, cuentas por pagar.
De esta forma hemos ayudado a nuestros clientes a entender la correlación que existe entre una publicación pagada, su impacto en las redes sociales y la conversión de venta. El resultado final hacia nuestros clientes consiste en una estrategia de publicidad inteligente que les permite obtener un mayor retorno de inversión en publicidad.

Correlación: Asociación estadística que describe
la relación entre dos variables.

Aprendizaje supervisado: Entrenamiento de un
sistema a través de la alimentación de información identificada con etiquetas.

Aprendizaje supervisado: Entrenamiento de un
sistema a través de la alimentación de información identificada con etiquetas.
Segmentación de cartera de tarjetahabientes para
campañas de marketing
En Stratis hemos ayudado a nuestros clientes del sector Financiero a innovar su negocio a través de Machine Learning. En particular, hemos apoyado a nuestros clientes emisores de tarjetas de crédito a identificar segmentos de mercado que no han sido atendidos de forma óptima y que presentan una gran oportunidad de negocio. A partir de esta identificación hemos ayudado a maximizar el impacto de la inversión en campañas de marketing y esfuerzos de retención. Lo anterior se logró a partir de las siguientes actividades:
- Integración, creación, preparación y análisis exploratorio de variables para ser utilizadas en la construcción del modelo de segmentación (tarjetas y seguros).
- Enriquecimiento de los conjuntos de datos con variables que puedan ayudar a un mejor entendimiento del comportamiento de los clientes.
- Construcción de un modelo de segmentación (utilizando K-Means) para identificar los segmentos de los clientes (tarjetas y seguros) que comparten ciertas características.
- Proveer una guía de las recomendaciones para implementar los segmentos en producción.
- Monitoreo de desempeño y mantenimiento del modelo.


Aprendizaje supervisado: Entrenamiento de un sistema a través de la alimentación de información identificada con etiquetas.

Agrupamiento: Colección de datos en grupos basada en la similitud entre ellos.
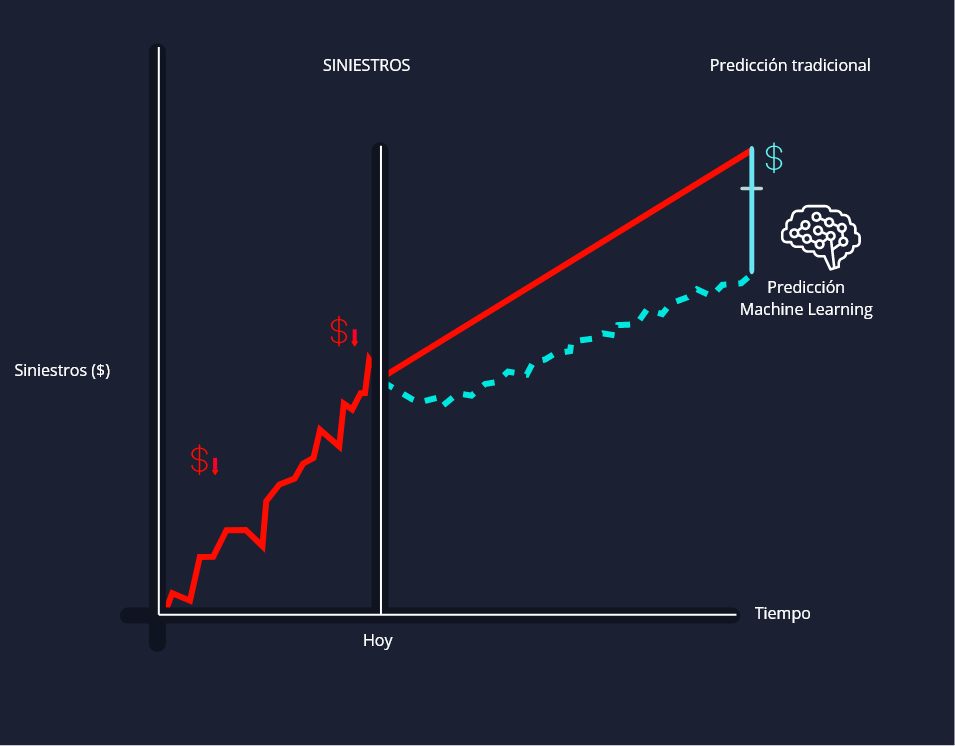
Predicción de Siniestralidad para Aseguradoras
En Stratis hemos ayudado a nuestros clientes de la industria de seguros a predecir la siniestralidad total de su cartera de forma más precisa a través de la implementación de un modelo de definición de valor presente de pólizas multianuales. Al tener una visión informada del comportamiento a futuro de la siniestralidad, nuestros clientes han optimizado sus reservas para así liberar la mayor cantidad de recursos financieros y al mismo tiempo cumplir estrictamente con la normatividad establecida. Lo anterior se logró a través de las siguientes actividades:
- Inclusión de variables endógenas y exógenas al modelo (Cajas de Valores).
- Inclusión del estado de resultados y cálculo del valor presente.
- Procedimientos que permiten visualizar el ajuste de las curvas (Siniestros, Severidad) con diferentes modelos de distribución y generación de percentiles.
- Elaboración de un proceso para predecir la rentabilidad esperada a partir de distintos escenarios.
- Monitoreo de desempeño y mantenimiento del modelo.

Aprendizaje supervisado: Entrenamiento de un sistema a través de la alimentación de información identificada con etiquetas.

Regresión: Predicción de una variable cuantitativa mediante la identificación de relaciones entre valores conocidos.